Organic HPC
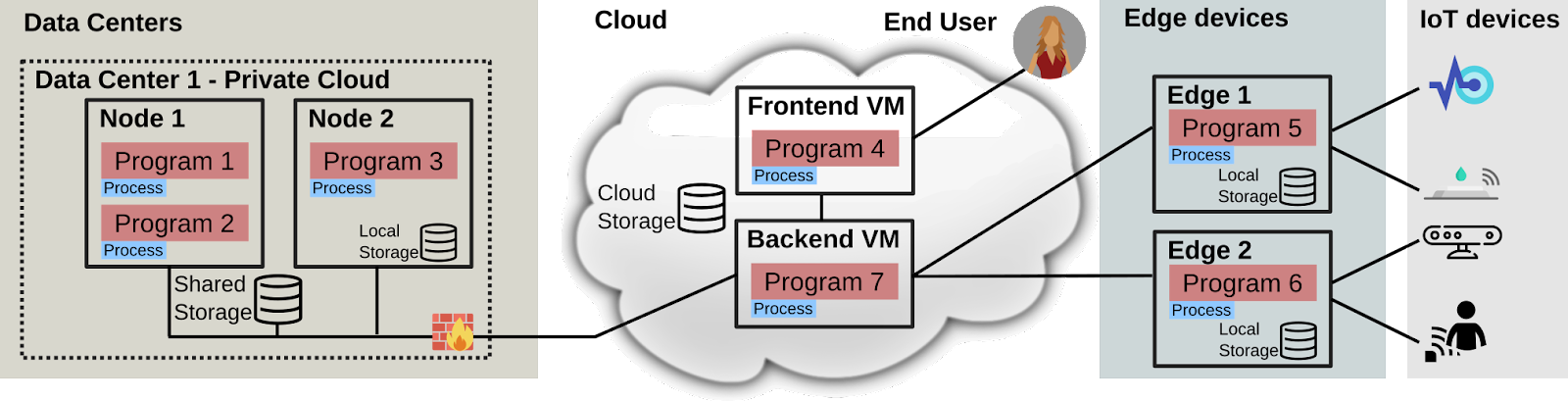
High-Performance Computing usually happens in HPC data centers on compute clusters consisting of powerful machines. However, depending on the nature of an HPC workflow and how many other users are accessing a compute cluster in parallel, such a data center might not be able to optimally serve all users. Instead of expanding the data center, it could instead form a compute continuum with other computing resources such as cloud and edge computers. Together these constitute a heterogeneous cluster that is able to serve many more use cases than a data center alone can.
This brings another challenge: The dynamic management of such a compute cluster to ensure that the placement of HPC jobs, workloads, and data is optimized. The two main issues here are modeling the state of the system, including information on the network speed, as well as, making as close to optimal decisions on the placement of jobs and data in real-time as possible. The network model needs to be able to indicate the available bandwidth between any two nodes while still being scalable for thousands of compute nodes and being able to dynamically update itself when the system topology changes. Optimal placement of workloads is considered to be an NP-complete problem such that even with smart mathematical algorithms, it is not possible to quickly find optimal decisions for large clusters. Instead, a compromise is needed, trading optimal for near-optimal and using heuristic and machine learning algorithms that are able to compute more quickly even on scale.
The successful design and implementation of such a system would enable use cases such as the live processing of data from edge nodes using cloud and data center resources, while also actively optimizing where said data is stored and processed. Furthermore, it also enables HPC jobs, running on a data center, to dynamically include cloud and edge nodes to temporarily increase their compute capacity. By stretching and distributing workflows as well as storage across arbitrary devices, the compute continuum is able to utilize said devices for data input, processing, and storage.
We call this concept Organic HPC as such a system would dynamically adjust itself to a changing hardware landscape as if it were alive.
Thus, Organic HPC describes a system comprised of various heterogeneous components potentially spanning multiple locations including data centers with HPC resources and cloud and edge in which compute jobs consisting of many tasks are automatically and dynamically distributed across the available hardware resources according to their performance characteristics.